텍스트 분석에서 가장 단순하고 기본적인 아이디어는 하나 혹은 여러개의 문서에서 가장 많이 사용된 단어를 파악하는 것이므로 한때 유행이었고 현재도 보여주기에 좋은 방법 중 하나이다.
3.1. 단어 빈도 그래프 - 많이 쓰인 단어는?
단어 빈도를 구하려면 먼저 문서들로부터 각 단어들을 분리
앞장에서 배운 토큰화, 어간 추출, 불용어 등을 사용해보자.
아래 코드는 저작권이 만료된 구텐베르크 프로젝트에 있는 책들이며 텍스트 마이닝 연습하기에 좋다.
import nltk
nltk.download('gutenberg')
from nltk.corpus import gutenberg
file_names = gutenberg.fileids() #파일 제목을 읽어온다.
print(file_names)
"""
['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-kjv.txt', 'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt', 'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt', 'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt', 'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt', 'shakespeare-macbeth.txt', 'whitman-leaves.txt']
"""
doc_alice = gutenberg.open('carroll-alice.txt').read()
print('#Num of characters used:', len(doc_alice))
# 사용된 문자의 수 print('#Text sample:')
print(doc_alice[:500])
#앞의 500자만 출력
#Num of characters used: 144395
"""
[Alice's Adventures in Wonderland by Lewis Carroll 1865]
CHAPTER I. Down the Rabbit-Hole
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy an
"""
내용을 확인하고 NLTK를 이용해 토큰화 한다.
토큰 수와 앞 20개의 토큰을 확인하고 위에서 본 앞부분 내용과 비교해본다.
from nltk.tokenize import word_tokenize
tokens_alice = word_tokenize(doc_alice) #토큰화 실행
print('#Num of tokens used:', len(tokens_alice))
print('#Token sample:')
print(tokens_alice[:20])
"""
# Num of tokens used: 33494
# Token sample:
['[', 'Alice', "'s", 'Adventures', 'in', 'Wonderland', 'by', 'Lewis', 'Carroll', '1865', ']', 'CHAPTER', 'I', '.', 'Down', 'the', 'Rabbit-Hole', 'Alice', 'was', 'beginning']
"""
포터 스테머로 스테밍하고, 토큰 수와 앞 20개의 토큰을 확인한다.
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
# 모든 토큰에 대해 스테밍 실행
stem_tokens_alice = [stemmer.stem(token) for token in tokens_alice]
print('#Num of tokens after stemming:', len(stem_tokens_alice))
print('#Token sample:')
print(stem_tokens_alice[:20])
"""
# Num of tokens after stemming: 33494
# Token sample:
['[', 'alic', "'s", 'adventur', 'in', 'wonderland', 'by', 'lewi', 'carrol', '1865', ']', 'chapter', 'i', '.', 'down', 'the', 'rabbit-hol', 'alic', 'wa', 'begin']
"""
WordNetLemmatizer를 이용해 표제어를 추출하고, 토큰 수와 앞 20개의 토큰을 스테밍 결과와 비교한다.
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
# 모든 토큰에 대해 스테밍 실행
lem_tokens_alice = [lemmatizer.lemmatize(token) for token in tokens_alice]
print('#Num of tokens after lemmatization:', len(lem_tokens_alice))
print('#Token sample:')
print(lem_tokens_alice[:20])
"""
# Num of tokens after lemmatization: 33494
# Token sample:
['[', 'Alice', "'s", 'Adventures', 'in', 'Wonderland', 'by', 'Lewis', 'Carroll', '1865', ']', 'CHAPTER', 'I', '.', 'Down', 'the', 'Rabbit-Hole', 'Alice', 'wa', 'beginning']
"""
앞 장에서 배운 3개 미만 글자를 다 지우는 정규표현식을 적용하고 확인해보자.
from nltk.tokenize import RegexpTokenizer
tokenizer = RegexpTokenizer("[\\\\w']{3,}")
reg_tokens_alice = tokenizer.tokenize(doc_alice.lower())
print('#Num of tokens with RegexpTokenizer:', len(reg_tokens_alice))
print('#Token sample:')
print(reg_tokens_alice[:20])
"""
# Num of tokens with RegexpTokenizer: 21616
# Token sample:
["alice's", 'adventures', 'wonderland', 'lewis', 'carroll', '1865', 'chapter', 'down', 'the', 'rabbit', 'hole', 'alice', 'was', 'beginning', 'get', 'very', 'tired', 'sitting', 'her', 'sister']
"""
여기서는 그래프를 보여주는것이 목적이기에 부호를 없애고 그 결과에서 불용어를 제거하자
from nltk.corpus import stopwords # 일반적으로 분석대상이 아닌 단어들
english_stops = set(stopwords.words('english')) # 반복되지 않게 set으로 변환
# stopwords를 제외한 단어들만으로 리스트를 생성
result_alice = [word for word in reg_tokens_alice if word not in english_stops]
print('#Num of tokens after stopword elimination:', len(result_alice))
print('#Token sample:')
print(result_alice[:20])
"""
#Num of tokens after stopword elimination: 12999
#Token sample:
["alice's", 'adventures', 'wonderland', 'lewis', 'carroll', '1865', 'chapter', 'rabbit', 'hole', 'alice', 'beginning', 'get', 'tired', 'sitting', 'sister', 'bank', 'nothing', 'twice', 'peeped', 'book']
"""
텍스트 전처리가 완료되었으니 각 단어별로 빈도를 계산한다.
딕셔너리로 단어별 개수를 세고, 비도가 큰 순으로 정렬한다.
alice_word_count = dict()
for word in result_alice:
alice_word_count[word] = alice_word_count.get(word, 0) + 1
print('#Num of used words:', len(alice_word_count))
sorted_word_count = sorted(alice_word_count, key=alice_word_count.get, reverse=True)
print("#Top 20 high frequency words:")
for key in sorted_word_count[:20]: #빈도수 상위 20개의 단어를 출력
print(f'{repr(key)}: {alice_word_count[key]}', end=', ')
"""
#Num of used words: 2687
#Top 20 high frequency words:
'said': 462, 'alice': 385, 'little': 128, 'one': 98, 'know': 88, 'like': 85, 'went': 83, 'would': 78, 'could': 77, 'thought': 74, 'time': 71, 'queen': 68, 'see': 67, 'king': 61, 'began': 58, 'turtle': 57, "'and": 56, 'way': 56, 'mock': 56, 'quite': 55,
"""
위 결과를 보면 would, could, and와 같은 별 필요하지 않는 단어들이 올라와 있다.
그래프에서 필요한건 보통 명사, 동사, 형용사이니 이것들만 추출해보자.
my_tag_set = ['NN', 'VB', 'VBD', 'JJ']
my_words = [word for word, tag in nltk.pos_tag(result_alice) if tag in my_tag_set]
alice_word_count = dict()
for word in my_words:
alice_word_count[word] = alice_word_count.get(word, 0) + 1
print('#Num of used words:', len(alice_word_count))
sorted_word_count = sorted(alice_word_count, key=alice_word_count.get, reverse=True)
print("#Top 20 high frequency words:")
for key in sorted_word_count[:20]: # 빈도수 상위 20개의 단어를 출력
print(f'{repr(key)}: {alice_word_count[key]}', end=', ')
"""
#Num of used words: 1726
#Top 20 high frequency words:
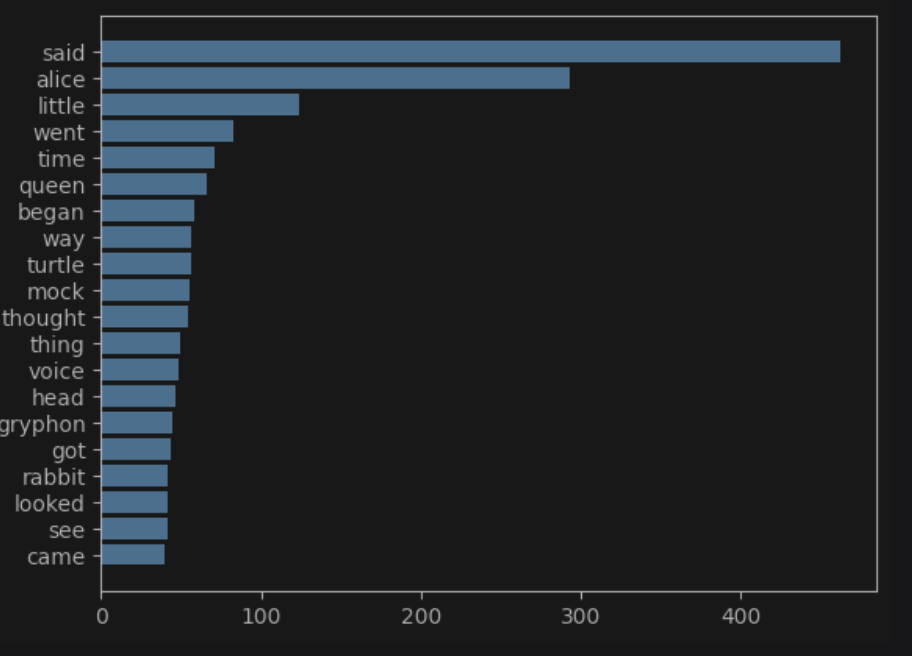
'said': 462, 'alice': 293, 'little': 124, 'went': 83, 'time': 71, 'queen': 66, 'began': 58, 'way': 56, 'turtle': 56, 'mock': 55, 'thought': 54, 'thing': 49, 'voice': 48, 'head': 46, 'gryphon': 45, 'got': 44, 'rabbit': 42, 'looked': 42, 'see': 42, 'came': 40,
"""
결과가 만족스럽지 않지만 그래프로 그려보자
import matplotlib.pyplot as plt
%matplotlib inline
# 정렬된 단어 리스트에 대해 빈도수를 가져와서 리스트 생성
w = [alice_word_count[key] for key in sorted_word_count]
plt.plot(w)
plt.show()
위 그래프로는 뭔가 알수 있는게 없다.
단어가 무엇인지 모르며, 출력한다해도 단어가 많아서 알기 어렵다.
빈도수가 높은 상위 단어들만 출력해서 그려야 한다.
그래프를 좀 실용적으로 바꾸어 보자
n = sorted_word_count[:20][::-1] # 빈도수 상위 20개의 단어를 추출해 역순으로 정렬
w = [alice_word_count[key] for key in n] # 20개 단어에 대한 빈도
plt.barh(range(len(n)),w,tick_label=n) # 수평 막대그래프
plt.show()
3.2. 워드 클라우드로 내용을 한눈에 보기
텍스트 분석 결과를 보여주는 활용도가 높은 시각화 도구
from wordcloud import WordCloud
# 워드 클라우드 이미지 생성
wordcloud = WordCloud().generate(doc_alice)
plt.axis("off")
plt.imshow(wordcloud, interpolation='bilinear') # 이미지를 출력
plt.show()
나쁘지 않으나 generate 메서드에 입력으로 토큰화를 알아서 해준다.
generate_from_frequencies를 사용하면 계산된 빈도를 이용해서 그려준다.
import numpy as np
from PIL import Image
# 배경이미지를 불러와서 넘파이 array로 변환
alice_mask = np.array(Image.open("alice_mask.png"))
wc = WordCloud(background_color="white", # 배경색 지정
max_words=30, # 출력할 최대 단어 수
mask=alice_mask, # 배경으로 사용할 이미지
contour_width=3, # 테두리 굵기
contour_color='steelblue') # 테두리 색
wc.generate_from_frequencies(alice_word_count) # 워드 클라우드 생성
wc.to_file("alice.png") # 결과를 이미지 파일로 저장
# 화면에 결과를 출력
plt.figure()
plt.axis("off")
plt.imshow(wc, interpolation='bilinear')
plt.show()
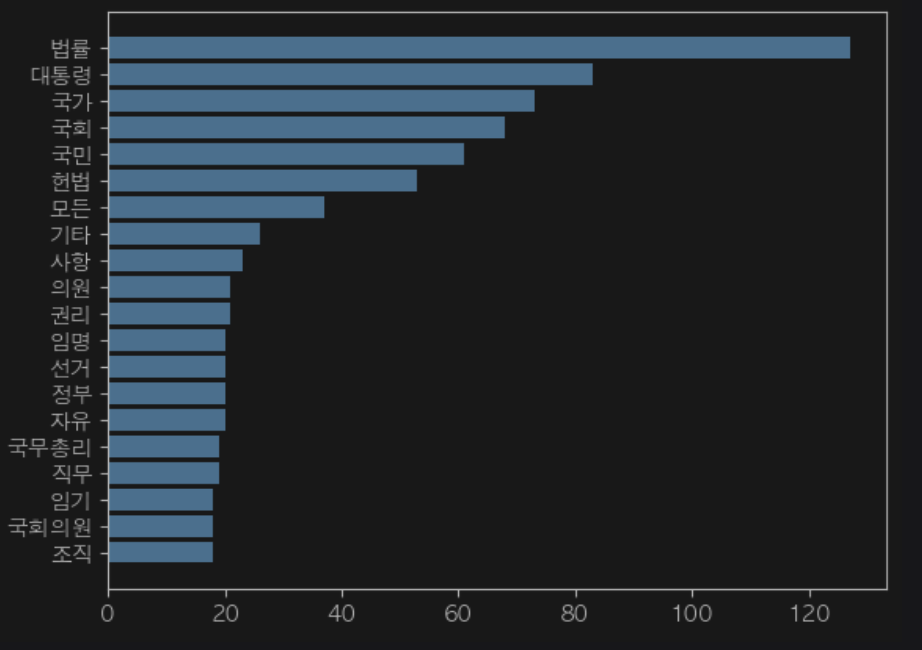
3.3. 한국어 문서에 대한 그래프와 워드 클라우드
KoNLPy에서 헌법 텍스트를 불러오고 타입과 문자 수 앞 일부분 등 확인하자.
from konlpy.corpus import kolaw
const_doc = kolaw.open('constitution.txt').read()
print(type(const_doc)) # 가져온 데이터의 type을 확인 print(len(const_doc))
print(const_doc[:600])
"""
<class 'str'>
대한민국헌법
유구한 역사와 전통에 빛나는 우리 대한국민은 3·1운동으로 건립된 대한민국임시정부의 법통과 불의에 항거한 4·19민주이념을 계승하고, 조국의 민주개혁과 평화적 통일의 사명에 입각하여 정의·인도와 동포애로써 민족의 단결을 공고히 하고, 모든 사회적 폐습과 불의를 타파하며, 자율과 조화를 바탕으로 자유민주적 기본질서를 더욱 확고히 하여 정치·경제·사회·문화의 모든 영역에 있어서 각인의 기회를 균등히 하고, 능력을 최고도로 발휘하게 하며, 자유와 권리에 따르는 책임과 의무를 완수하게 하여, 안으로는 국민생활의 균등한 향상을 기하고 밖으로는 항구적인 세계평화와 인류공영에 이바지함으로써 우리들과 우리들의 자손의 안전과 자유와 행복을 영원히 확보할 것을 다짐하면서 1948년 7월 12일에 제정되고 8차에 걸쳐 개정된 헌법을 이제 국회의 의결을 거쳐 국민투표에 의하여 개정한다.
제1장 총강
제1조 ① 대한민국은 민주공화국이다.
②대한민국의 주권은 국민에게 있고, 모든 권력은 국민으로부터 나온다.
제2조 ① 대한민국의 국민이 되는 요건은 법률로 정한다.
②국가는 법률이 정하는 바에 의하여 재외국민을 보호할 의무를 진다.
제3조 대한민
"""